AmplifyにおけるBedrockの呼び出し方法を比較してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、つくぼし(tsukuboshi0755)です!
最近Amplify Gen 2とBedrockを統合し、AWS内で完結する生成AIアプリを個人的に開発する機会があります。
Amplifyの公式ドキュメントでBedrockとの連携を調べていた所、主に2つの呼び出し方法がある事を知りました。
この呼び出し方法について、状況に応じてどれを使えばいいのかという疑問があったので、今回はその違いを調べてみます!
Amplifyにおける他AWSサービスとの統合
始めにAmplifyにおける他AWSサービスとの統合について説明します。
Amplify Gen 2では、他のAWSサービスと連携するためにAmplify Dataという機能が提供されてます。
このAmplify Dataは裏側でAppSyncと連携し、GraphQLのスキーマで受けたリクエストに対してデータを操作するGraphQL APIリゾルバーを用いる事で、他のAWSサービスを呼び出す事が可能です。
Amplify Dataの詳細については、以下の記事をご参照ください。
また上記のリゾルバーは通常VTL(Velocity Template Language)と呼ばれる独自言語を用いてやりとりをするため、Amplify Gen 1ではVTLを記述する必要がありました。
しかしAmplify Gen 2でAppSync JavaScriptリゾルバーに対応した事で、VTLの代わりにJavaScriptを用いて記述する事が可能になっています。
JavaScriptリゾルバーの詳細については、以下の記事をご参照ください。
Bedrockの呼び出し方法
上記で示したGraphQL APIリゾルバーの内、Bedrockを呼び出す主要なリゾルバーは以下の2種類です。
- カスタムリゾルバー(HTTPリゾルバー)
- Amplify Function(Lambdaリゾルバー)
各々のリゾルバーについて、以下で詳しく説明します。
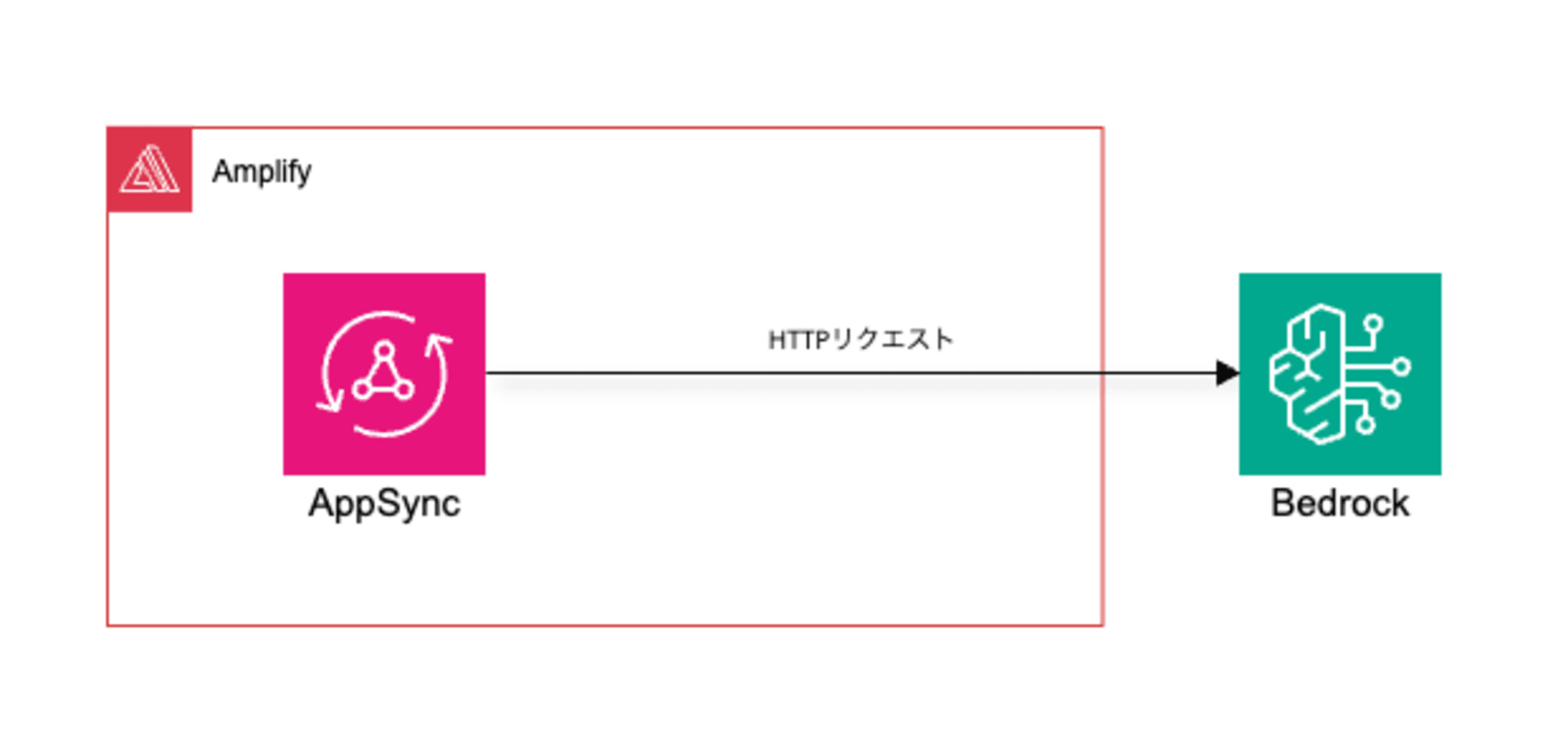
カスタムリゾルバー(HTTPリゾルバー)
こちらはAppSyncのリゾルバーでBedrockエンドポイントにHTTPリクエストを送付し、直接Bedrockを呼び出す方法です。
この場合AppSyncのデータソースタイプとして、HTTPエンドポイントが指定されます。
イメージ図としては以下の通りです。
Amplifyのコードでは、以下のように定義します。
まずamplify/backend.ts内で、AppSyncのデータソースにBedrockのエンドポイントを指定し、Bedrockへのアクセス権限を付与します。
import { defineBackend } from "@aws-amplify/backend";
import { auth } from "./auth/resource";
import { data } from "./data/resource";
import { Effect, PolicyStatement } from "aws-cdk-lib/aws-iam";
import { Stack } from "aws-cdk-lib";
export const backend = defineBackend({
auth,
data,
});
const MODEL_ID = "anthropic.claude-3-haiku-20240307-v1:0";
const bedrockDataSource = backend.data.addHttpDataSource(
"BedrockDataSource",
"https://bedrock-runtime.us-east-1.amazonaws.com",
{
authorizationConfig: {
signingRegion: Stack.of(backend.data).region,
signingServiceName: "bedrock",
},
}
);
bedrockDataSource.grantPrincipal.addToPrincipalPolicy(
new PolicyStatement({
effect: Effect.ALLOW,
actions: ["bedrock:InvokeModel"],
resources: [
`arn:aws:bedrock:${Stack.of(backend.data).region}::foundation-model/${MODEL_ID}`,
],
})
);
backend.data.resources.cfnResources.cfnGraphqlApi.environmentVariables = {
MODEL_ID
}
続いてts:amplify/data/resource.ts内で、a.handler.custom()修飾子で使用するデータソース名とリゾルバーのエントリーポイントを指定します。
import { type ClientSchema, a, defineData } from "@aws-amplify/backend";
const schema = a.schema({
generateHaiku: a
.query()
.arguments({ prompt: a.string().required() })
.returns(a.string())
.authorization((allow) => [allow.publicApiKey()])
.handler(
a.handler.custom({
dataSource: "BedrockDataSource",
entry: "./generateHaiku.js",
})
),
});
export type Schema = ClientSchema<typeof schema>;
export const data = defineData({
schema,
authorizationModes: {
defaultAuthorizationMode: "apiKey",
apiKeyAuthorizationMode: {
expiresInDays: 30,
},
},
});
最後にデータソースから呼び出すエントリーポイント内で、リソースパスを指定したPOSTリクエストを使用してBedrockを呼び出します。
export function request(ctx) {
// Define a system prompt to give the model a persona
const system =
"You are a an expert at crafting a haiku. You are able to craft a haiku out of anything and therefore answer only in haiku.";
const prompt = ctx.args.prompt
// Construct the HTTP request to invoke the generative AI model
return {
resourcePath: `/model/${ctx.env.MODEL_ID}/invoke`,
method: "POST",
params: {
headers: {
"Content-Type": "application/json",
},
body: {
anthropic_version: "bedrock-2023-05-31",
system,
messages: [
{
role: "user",
content: [
{
type: "text",
text: prompt,
},
],
},
],
max_tokens: 1000,
temperature: 0.5,
},
},
};
}
// Parse the response and return the generated haiku
export function response(ctx) {
const res = JSON.parse(ctx.result.body);
const haiku = res.content[0].text;
return haiku;
}
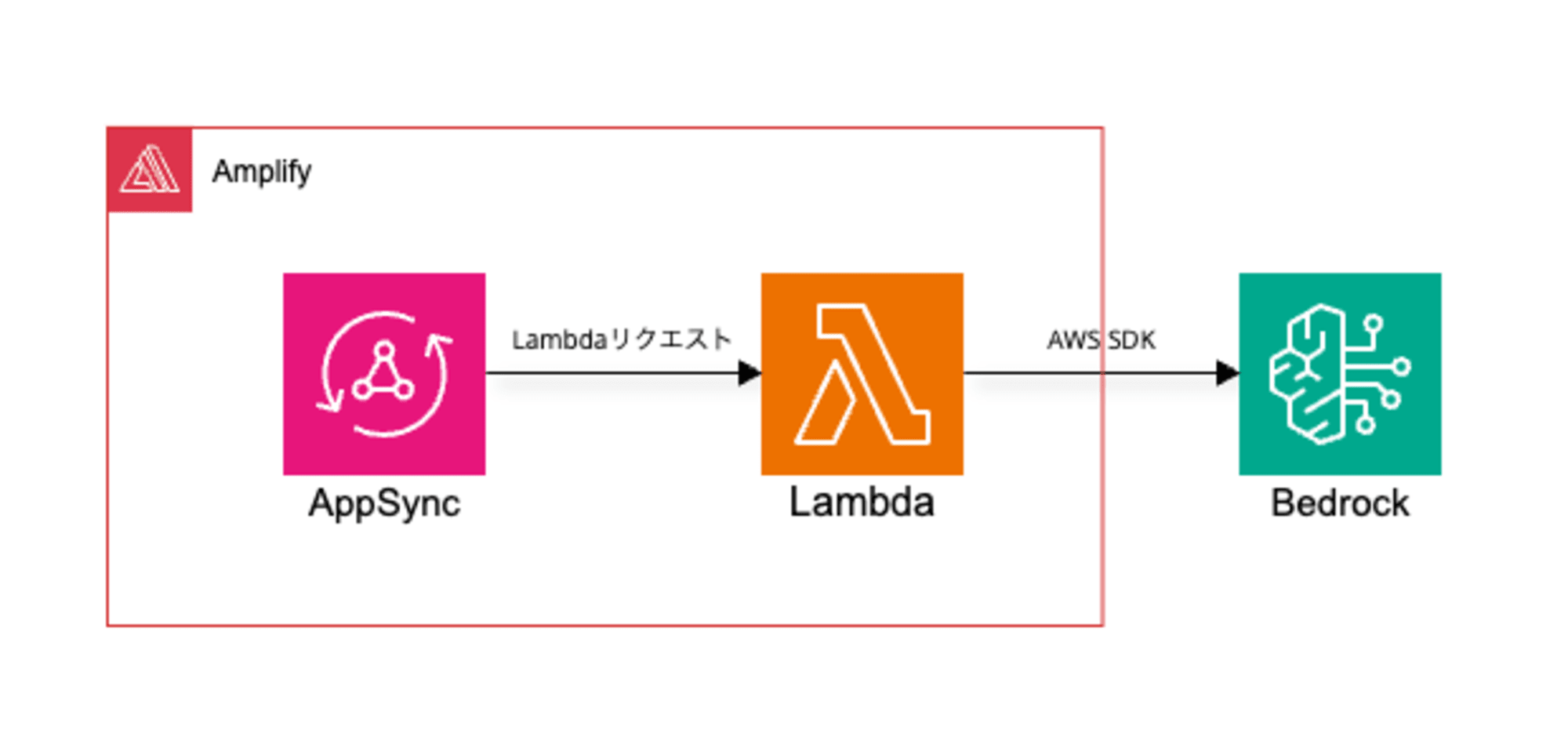
Amplify Function(Lambdaリゾルバー)
こちらはAppSyncのリゾルバーからLambda関数を呼び出し、AWS SDKのBedrock APIを実行する事で間接的にAWSサービスを呼び出す方法です。
この場合AppSyncのデータソースタイプとして、Lambda関数が指定されます。
またAmplifyコンソール上でも、Function項目で表示されるようになります。
イメージ図としては以下の通りです。
Amplifyのコードでは、以下のように定義します。
まずamplify/backend.tsにて、バックエンドにLambda関数を追加し、Bedrockへのアクセス権限を付与します。
import { defineBackend } from "@aws-amplify/backend";
import { auth } from "./auth/resource";
import { data, MODEL_ID, generateHaikuFunction } from "./data/resource";
import { Effect, PolicyStatement } from "aws-cdk-lib/aws-iam";
export const backend = defineBackend({
auth,
data,
generateHaikuFunction,
});
backend.generateHaikuFunction.resources.lambda.addToRolePolicy(
new PolicyStatement({
effect: Effect.ALLOW,
actions: ["bedrock:InvokeModel"],
resources: [
`arn:aws:bedrock:*::foundation-model/${MODEL_ID}`,
],
})
);
続いてts:amplify/data/resource.ts内で、a.handler.function()修飾子で使用するハンドラーとしてLambda関数を指定します。
import {
type ClientSchema,
a,
defineData,
defineFunction,
} from "@aws-amplify/backend";
export const MODEL_ID = "anthropic.claude-3-haiku-20240307-v1:0";
export const generateHaikuFunction = defineFunction({
entry: "./generateHaiku.ts",
environment: {
MODEL_ID,
},
});
const schema = a.schema({
generateHaiku: a
.query()
.arguments({ prompt: a.string().required() })
.returns(a.string())
.authorization((allow) => [allow.publicApiKey()])
.handler(a.handler.function(generateHaikuFunction)),
});
export type Schema = ClientSchema<typeof schema>;
export const data = defineData({
schema,
authorizationModes: {
defaultAuthorizationMode: "apiKey",
apiKeyAuthorizationMode: {
expiresInDays: 30,
},
},
});
最後にデータソースから呼び出すLambda関数内で、AWS SDKのInvokeModelCommand APIを使用してBedrockを呼び出します。
import type { Schema } from "./resource";
import {
BedrockRuntimeClient,
InvokeModelCommand,
InvokeModelCommandInput,
} from "@aws-sdk/client-bedrock-runtime";
// initialize bedrock runtime client
const client = new BedrockRuntimeClient();
export const handler: Schema["generateHaiku"]["functionHandler"] = async (
event,
context
) => {
// User prompt
const prompt = event.arguments.prompt;
// Invoke model
const input = {
modelId: process.env.MODEL_ID,
contentType: "application/json",
accept: "application/json",
body: JSON.stringify({
anthropic_version: "bedrock-2023-05-31",
system:
"You are a an expert at crafting a haiku. You are able to craft a haiku out of anything and therefore answer only in haiku.",
messages: [
{
role: "user",
content: [
{
type: "text",
text: prompt,
},
],
},
],
max_tokens: 1000,
temperature: 0.5,
}),
} as InvokeModelCommandInput;
const command = new InvokeModelCommand(input);
const response = await client.send(command);
// Parse the response and return the generated haiku
const data = JSON.parse(Buffer.from(response.body).toString());
return data.content[0].text;
};
呼び出し方法の比較
カスタムリゾルバーとAmplify Functionの比較表を以下に示します。
| 比較項目 | カスタムリゾルバー (HTTPリゾルバー) |
Amplify Function (Lambdaリゾルバー) |
|---|---|---|
| ランタイム | APPSYNC_JS (JavaScript)のみ | Lambdaでサポートされているランタイム全て |
| コードの最大サイズ | AppSync関数毎に 32,000 文字 | Lambda関数毎に50 MB (zip圧縮、直接アップロード用) |
| ネットワークアクセス | 不可 | 可能 |
| ファイルシステムアクセス | 不可 | 可能 |
| コールドスタート | なし | あり(別途プロビジョニングされた同時実行を使用すればなし) |
| オートスケーリング | AppSyncが自動実行 | Lambdaの設定による |
| 価格 | 追加料金なし | Lambdaの使用料金が別途かかる |
詳細な比較表については、以下の公式ドキュメントも合わせてご参照ください。
上記の比較表や各呼び出し方法におけるコード定義の特徴を踏まえると、以下のような使い分けが考えられます。
- カスタムリゾルバーを使うべき場面
- 追加料金なしでAWSサービスを呼び出したい場合
- コールドスタートに関する追加設定なしで素早くレスポンスを返したい場合
- バックエンドリソースについて、AppSyncのみのシンプルな構成で完結させたい場合
- Amplify Functionを使うべき場面
- ネットワークアクセスやファイルシステムアクセスが必要な場合
- バックエンド言語にJavaScript以外を使用したい場合
- バックエンドリソースの更新なしで、AWSサービスエンドポイントを環境変数等で柔軟にカスタマイズしたい場合
状況に応じて、カスタムリゾルバーとAmplify Functionを選択する形が良さそうですね。
最後に
今回はAmplifyにおけるBedrockの呼び出し方法を比較してみました。
Amplify Gen 2では、他AWSサービスとの連携が容易になり、開発効率が向上しています。
ぜひAmplify Gen 2を使って、Bedrockと連携した生成AIアプリの開発を試してみてください!
以上、つくぼし(tsukuboshi0755)でした!